
如何提高非监督分类的精度
如何提高非监督分类的精度
一、分类后处理
1.类别的合并
— 同一类别中,光谱特征相差太大,需要再分类的时候作为几类进行分类,分类完成后再进行类别的合并。
2.筛滤(sieve)
— 去除离散的像元点。与用户给定的窗口大小有关。去除后的像元标记为“未分类”。
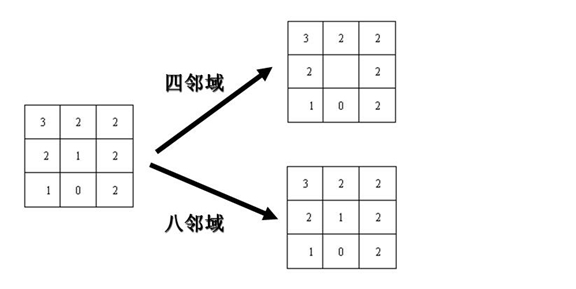
— 四邻域
— 八邻域
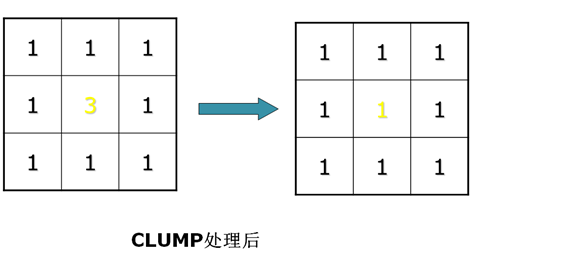
3.临近类别的归并(clump)
— 离散点归并到周围大的类别中。先膨胀,再侵蚀。
数学形态学知识简介:
— 膨胀(Dilate ):填充、扩展、增长等。填充小于结构元素(核)的像元。灰度图像或者黑白图像。
— 侵蚀(Erode ): 收缩。去除小于给定结构的孤岛。
— 开运算(Opening):先侵蚀再膨胀。突刺滤掉,切断细长搭接而起到分离作用。
— 闭运算(Closing):先膨胀再侵蚀。可以填补小的缺口和孔,搭接短的间断而起到连通作用。Clump采用闭运算
4.多数/少数分析Majority/Minority Analysis
— 多数或者少数分析
— 中心像元将被给定的窗口内的多数像元或者少数像元值所取代。
— 举例
5.类别叠加显示
— 将分类的图像叠加在一个彩色合成遥感图像上。对于分类图像可以选择要叠加的类别。
— 用途:动态变化的监测,分类结果的检验与交互式修改。
二、精度评价
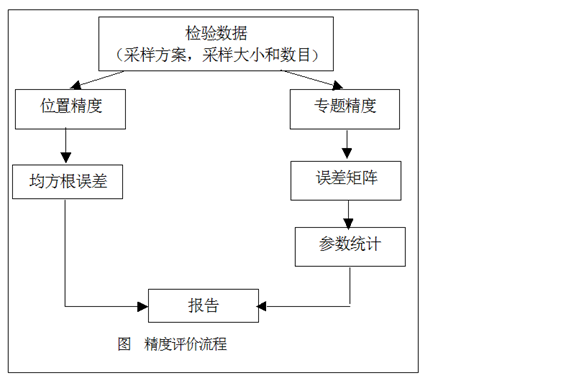
1.精度评价流程
分类精度直接关系到更新GIS数据库的能力,说明分类结果的可信度。
2.检验数据
检验数据和遥感分类结果对比,形成混淆矩阵,评价遥感图像分类结果。
1)检验数据
检验数据主要来自于地面实况的调查或更高空间分辨率的航空图像的目视解译结果。
ENVI软件中通过定义ROI来实现。
3.采样方法
①来自监督分类的训练样区
②专门选定的试验场
③随机取样
检验样本的采样方法是影响精度评价结果的重要因素。
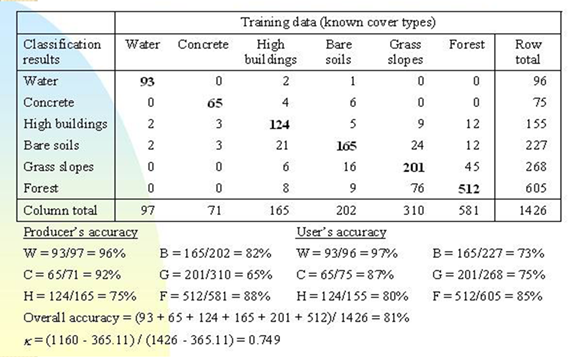
4.混淆矩阵
采用某种采样方法得到检验数据,对比遥感分类结果图得到混淆矩阵。混淆矩阵的形式如表。
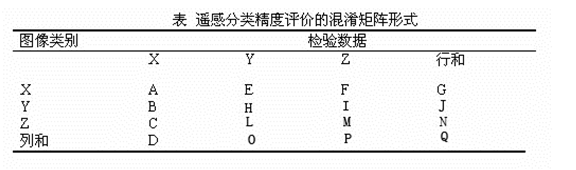
运行误差(Commit Error)=(E+F)/G
用户精度(User’s Accuracy):=A/G =100%-运行误差
结果误差(Omission Error)= (B+C)/D
生产者精度(Producer’s Accuracy)= A/D =100%-结果误差
总体精度(Overall Accuracy) = 正确分类/总样本数
5.Kappa统计
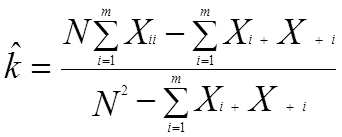 总体精度并不能排除偶然一致性,Cohen(1960)提出的kappa统计评价方法。kappa统计也是根据混淆矩阵来计算。
总体精度并不能排除偶然一致性,Cohen(1960)提出的kappa统计评价方法。kappa统计也是根据混淆矩阵来计算。
其中m为类别数, X ii为对角线样本的数目,Xi+,X+i分别是i行i列上样本数目的总和,N为样本数目。
— Kappa统计用到了混淆矩阵中每一个元素,用来度量实际吻合(Actual Agreement)和变化吻合(Change Agreement),比只计算总体精度要合理些。总体精度只考虑混淆矩阵对角线上元素,kappa系数考虑了非对角线上的元素
— Kappa统计的意义是:如果Kappa统计为0.7,则表示所用的分类方法比随机赋予各点某一类别的方法优越70%。目前kappa统计也成为评价分类结果的一个标准参数。
6.分类精度评价
提高分类精度的策略
(1)、分类前的遥感图像预处理
— 遥感图像的预处理,几何校正,辐射校正
— 图像特征变换,主成分变换,NDVI
— 空间信息的提取与利用
(2)、分类树,分层分类
— 当一次性分类出现类间混淆又难以解决时,可以采用逐次分类的方法
(3)、不同的分类方法结合
— 监督分类与非监督分类结合:混合分类
(4)、多种信息复合
— 遥感信息
— 非遥感信息:其它地理辅助信息;比如DEM,坡度,土壤类型图等。


遥感官方微信
免费咨询:400-805-2218 桂公网安备 45030502000451号
桂公网安备 45030502000451号